资料内容:
一、为什么需要进行pdf解析?
最近在探索ChatPDF和ChatDoc等方案的思路,也就是用LLM实现文档助手。在此记录一些难题和解决方案,首
先讲解主要思想,其次以问题+回答的形式展开。
二、为什么需要 对 pdf 进行解析?
当 利用 LLMs 实现用户与文档对话时,首要工作 就是 对 文档中内容 进行 解析 。
由于pdf是最通用,也是最复杂的文档形式,所以 对 pdf 进行解析 变成 利用LLM实现用户与文档对话 的 重中之
重 工作。
如何精确地回答用户关于文档的问题,不重也不漏?笔者认为非常重要的一点是文档内容解析。如果内容都不能
很好地组织起来,LLM只能瞎编。
三、pdf解析 有哪些方法,对应的区别是什么?
pdf的解析大体上有两条路,一条是基于规则,一条是基于AI。
四、pdf解析 存在哪些问题?
pdf转text这块存在一定的偏差,尤其是paper中包含了大量的figure和table,以及一些特殊的字符,直接调用
langchain官方给的pdf解析工具,有一些信息甚至是错误的。
这里,一方面可以用arxiv的tex源码直接抽取内容,另一方面,可以尝试用各种ocr工具来提升表现。
五、如何 长文档(书籍)中关键信息?
对于 长文档(书籍),如何获取 其中关键信息,并构建索引:
• 方法一:基于规则:
• 介绍:根据文档的组织特点去“算”每部分的样式和内容
• 存在问题:不通用,因为pdf的类型、排版实在太多了,没办法穷举
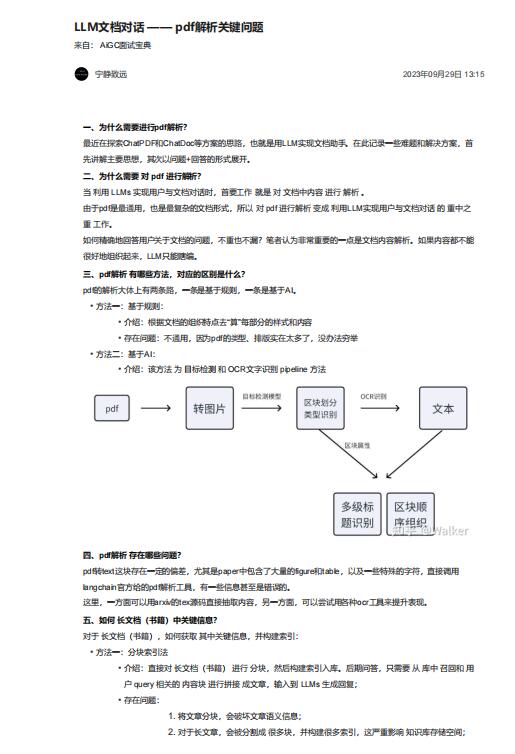
• 方法二:基于AI:
• 介绍:该方法 为 目标检测 和 OCR文字识别 pipeline 方法

