资料内容:
1.1 什么是Scrapy
Scrapy是一个为了爬取网站数据、提取结构性数据而编写的应用框架,可以应用在包括数据挖掘、信息
处理或存储历史数据等一系列的程序中。它是用Python实现的,最初是为了页面抓取(更确切来说,是网
络抓取)所设计的,也可以用于获取API所返回的数据(例如Amazon Associates Web Services)或者通用的
网络爬虫。
Scrapy的特点包括:
内置支持使用扩展的CSS选择器和XPath表达式从HTML/XML源码中选取提取数据
提供交互式shell控制台,用于调试选择器
内置支持生成多种格式的导出文件(JSON、CSV、XML)并存储在多种后端(FTP、S3、本地文件系统)
强大的编码支持和自动检测,用于处理外国的、非标准的和损坏的编码声明
可扩展性强,可以通过signals和API(中间件、扩展、管道)实现自定义功能
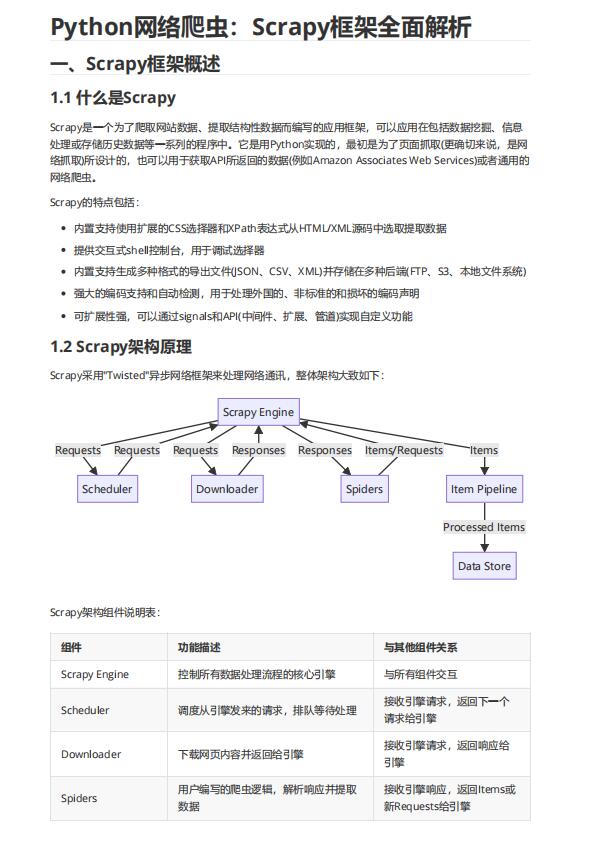
1.2 Scrapy架构原理
Scrapy采用"Twisted"异步网络框架来处理网络通讯,整体架构大致如下:

