1 背景介绍与spaCy安装
1.1 自然语言处理简介
自然语言处理(Natural Language Processing,简称NLP)是一门研究人类语言与计算机之间交互的领域,旨在使计算机能够理解、解析、生成和处理人类语言。NLP结合了计算机科学、人工智能和语言学的知识,通过各种算法和技术来处理和分析文本数据。近年来,随着深度学习技术的发展,神经网络模型在自然语言处理(NLP)领域取得了重大的突破。其中,循环神经网络(RNN)、长短时记忆网络(LSTM)和Transformer等模型都发挥了关键作用。这些模型为NLP任务带来了更好的性能和效果,推动了NLP的发展和应用。
NLP主要知识结构如下图所示,图片来自网络。
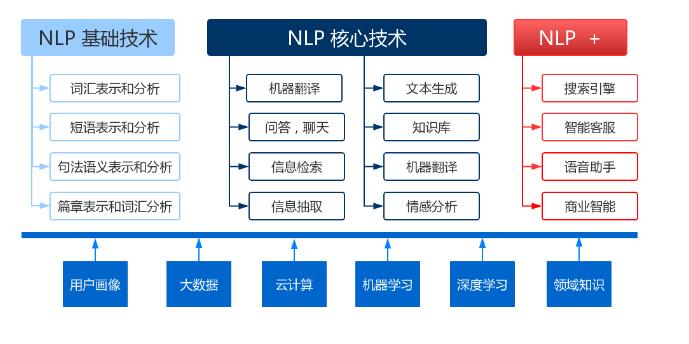
NLP的应用非常广泛,涵盖了多个领域,如机器翻译、信息提取、文本分类、情感分析、自动摘要、问答系统、语音识别和语音合成等。以下是NLP常用的技术和方法:
分词:将连续的文本分割成有意义的词语或标记,是许多NLP任务的基础。
词性标注:为文本中的每个词语赋予其相应的词性,如名词、动词、形容词等。
句法分析:分析句子的语法结构,识别出句子中的短语、修饰语和依存关系等。
语义分析:理解文本的意义和语义关系,包括命名实体识别、语义角色标注和语义解析等。
机器翻译:将一种语言的文本自动翻译成另一种语言。
文本分类:将文本按照预定义的类别进行分类,如垃圾邮件分类、情感分类等。
信息提取:从结构化和非结构化文本中提取出特定的信息,如实体关系抽取、事件抽取等。
问答系统:通过对用户提出的问题进行理解和回答,提供准确的答案或相关信息。
情感分析:识别和分析文本中的情感倾向,如正面、负面或中性情感。
文本生成:使用NLP技术生成自然语言文本,如自动摘要生成、对话系统和机器作文等。
在众多自然语言处理库中,spaCy库提供了超过73种语言的支持,并为25种语言提供了训练代码。该库提供了一系列简单易用的模型和函数接口,包括分词、词性标注等功能。用户还可以使用PyTorch、TensorFlow等框架在spaCy创建自定义模型,以满足特定需求。spaCy支持的语言模型见spaCy-models。
事实上,有一些自然语言处理开源库,例如HuggingFace的Transformers、PaddleNLP和NLTK,相较于spaCy来说更为专业且性能更好。然而,对于简单的应用而言,spaCy更为适合,因为它具有简单易用、功能全面,同时也提供了大量面向多语言预训练模型的优点。此外,随着以GPT-3为代表的语言大模型在自然语言处理领域取得了巨大的突破和成功,原本一些自然语言处理库在精度上实际不如语言大模型。然而,使用语言大模型需要庞大的推理资源,而在对精度要求不高的场景中,使用spaCy这类小巧的自然语言处理库依然是很合适的选择。
1.2 spaCy安装
spaCy采用采用模块和语言模块一起安装的模式。spaCy的设计目标之一是模块化和可定制性。它允许用户仅安装必需的模块和语言数据,以减少安装的整体大小和减轻资源负担。如果使用spaCy的模型,需要通过pip安装模型所需的模型包来使用预训练模型。这是因为spaCy的模型包含了训练后的权重参数和其他必要的文件,这些文件在安装时被存储在特定位置,而不是以单个文件的形式存在。如果需要进行模型训练和gpu运行则需要选定对应的安装包。将模块和语言模块一起安装,可以简化spaCy的配置过程。用户无需单独下载和配置语言数据,也不需要手动指定要使用的语言模型。这样可以减少用户的工作量和安装过程中的潜在错误。但是可定制性就很弱了,所以spaCy适合精度要求不高的简单使用,工程应用选择其他大型自然语言处理库更加合适。
为了实现这一目标,spaCy提供了配置化的安装指令选择页面供用户使用。安装指令选择页面地址为spaCy-usage。下图展示了本文的安装配置项,本文采用了最简单的cpu推理模式。
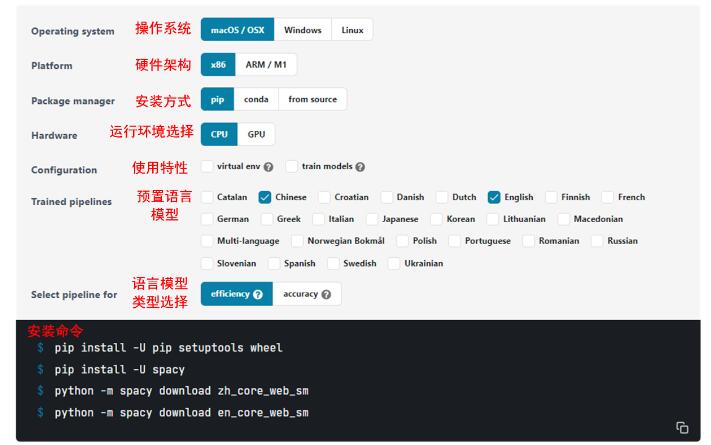
spaCy安装完毕后,运行以下代码即可判断spaCy及相对应的语言模型是否安装成功。
# jupyter notebook环境去除warning
import warnings
warnings.filterwarnings("ignore")
import spacy
spacy.__version__
'3.6.0'
import spacy
# 加载已安装的中文模型
nlp = spacy.load('zh_core_web_sm')
# 执行一些简单的NLP任务
doc = nlp("早上好!")
for token in doc:
# token.text表示标记的原始文本,token.pos_表示标记的词性(part-of-speech),token.dep_表示标记与其他标记之间的句法依存关系
print(token.text, token.pos_, token.dep_)
早上 NOUN nmod:tmod
好 VERB ROOT
! PUNCT punct
2 spaCy快速入门
该部分内容和图片主要来自于spacy-101的总结。spaCy提供的主要函数模块分为以下模块,接下来分别对这些模块进行介绍。
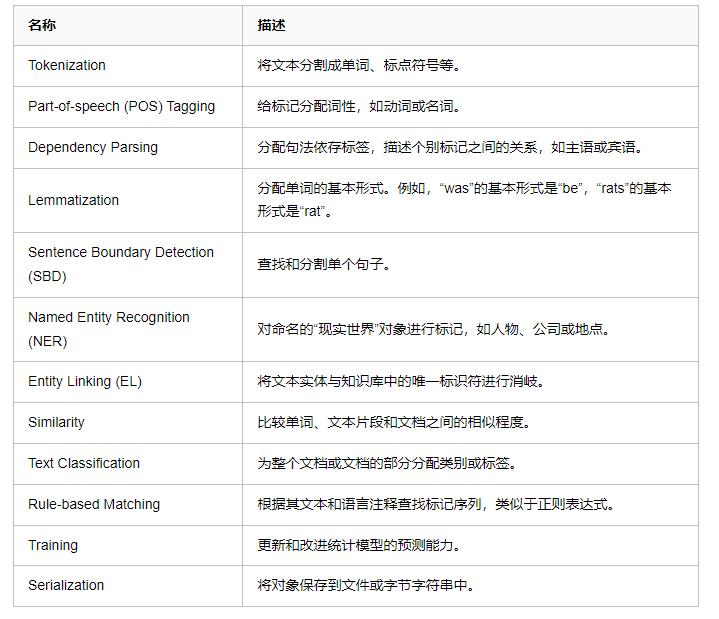
2.1 分词
在处理过程中,spaCy首先对文本进行标记,即将其分段为单词、标点符号等Token。这是通过应用每种语言特有的规则来实现的。Token表示自然语言文本的最小单位。每个Token都代表着文本中的一个原子元素,通常是单词或标点符号。
import spacy
nlp = spacy.load("zh_core_web_sm")
# 使对文本进行一键处理
doc = nlp("南京长江大桥是金陵四十景之一!")
# 遍历doc中的每个Token
for token in doc:
print(token.text)
南京
长江
大桥
是
金陵
四十
景
之一
!
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
for token in doc:
print(token.text)
Apple
is
looking
at
buying
U.K.
startup
for
$
1
billion
对于中文分词有时会出现专有名词被拆分,比如南京长江大桥被拆分为南京、长江、大桥。我们可以添加自定义词典来解决该问题,但是要注意的是自定义词典添加只针对某些语言模型。
import spacy
nlp = spacy.load("zh_core_web_sm")
# 添加自定义词汇
nlp.tokenizer.pkuseg_update_user_dict(["南京长江大桥","金陵四十景"])
doc = nlp("南京长江大桥是金陵四十景之一!")
for token in doc:
print(token.text)
南京长江大桥
是
金陵四十景
之一
!
2.2 词性标注与依存关系
spaCy在分词后,会对句子中每个词进行词性标注以及确定句子中单词之间的语法关系,要注意这些关系具体范围取决于所使用的模型。示例代码如下所示:
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("Apple is looking at buying U.K. startup for $1 billion")
# token.text: 单词的原始形式。
# token.lemma_: 单词的基本形式(或词干)。例如,“running”的词干是“run”。
# token.pos_: 单词的粗粒度的词性标注,如名词、动词、形容词等。
# token.tag_: 单词的细粒度的词性标注,提供更多的语法信息。
# token.dep_: 单词在句子中的依存关系角色,例如主语、宾语等。
# token.shape_: 单词的形状信息,例如,单词的大小写,是否有标点符号等。
# token.is_alpha: 这是一个布尔值,用于检查token是否全部由字母组成。
# token.is_stop: 这是一个布尔值,用于检查token是否为停用词(如“the”、“is”等在英语中非常常见但通常不包含太多信息的词)。
for token in doc:
print(token.text, token.lemma_, token.pos_, token.tag_, token.dep_,
token.shape_, token.is_alpha, token.is_stop)
Apple Apple PROPN NNP nsubj Xxxxx True False
is be AUX VBZ aux xx True True
looking look VERB VBG ROOT xxxx True False
at at ADP IN prep xx True True
buying buy VERB VBG pcomp xxxx True False
U.K. U.K. PROPN NNP dobj X.X. False False
startup startup NOUN NN advcl xxxx True False
for for ADP IN prep xxx True True
$ $ SYM $ quantmod $ False False
1 1 NUM CD compound d False False
billion billion NUM CD pobj xxxx True False
在上述代码中pos_所用是常见的单词词性标注。tag_所支持的词性标注及解释如下:
# 获取所有词性标注(tag_)和它们的描述
tag_descriptions = {tag: spacy.explain(tag) for tag in nlp.get_pipe('tagger').labels}
# 打印词性标注(tag_)及其描述
# print("词性标注 (TAG) 及其描述:")
# for tag, description in tag_descriptions.items():
# print(f"{tag}: {description}")
dep__所支持的依存关系及解释如下:
# 获取所有依存关系标注和它们的描述
par_descriptions = {par: spacy.explain(par) for par in nlp.get_pipe('parser').labels}
# print("依存关系及其描述:")
# for par, description in par_descriptions.items():
# print(f"{par}: {description}")
2.3 命名实体识别
命名实体识别(Named Entity Recognition, 简称NER)是自然语言处理中的一项基础任务,应用范围非常广泛。 NER是指识别文本中具有特定意义或者指代性强的实体,通常包括人名、地名、机构名、日期时间、专有名词等。spaCy使用如下:
import spacy
nlp = spacy.load("zh_core_web_sm")
# 添加自定义词汇
nlp.tokenizer.pkuseg_update_user_dict(["东方明珠"])
# 自定义词汇可能不会进入实体识别。
doc = nlp("东方明珠是一座位于中国上海市的标志性建筑,建造于1991年,是一座高度为468米的电视塔。")
for ent in doc.ents:
# 实体文本,开始位置,结束位置,实体标签
print(ent.text, ent.start_char, ent.end_char, ent.label_)
中国上海市 9 14 GPE
1991年 24 29 DATE
468米 36 40 QUANTITY
如果想知道所有的实体以及其对应的含义,可以执行以下代码:
# 获取命名实体标签及其含义
entity_labels = nlp.get_pipe('ner').labels
# 打印输出所有命名实体及其含义
for label in entity_labels:
print("{}: {}".format(label,spacy.explain(label)))
CARDINAL: Numerals that do not fall under another type
DATE: Absolute or relative dates or periods
EVENT: Named hurricanes, battles, wars, sports events, etc.
FAC: Buildings, airports, highways, bridges, etc.
GPE: Countries, cities, states
LANGUAGE: Any named language
LAW: Named documents made into laws.
LOC: Non-GPE locations, mountain ranges, bodies of water
MONEY: Monetary values, including unit
NORP: Nationalities or religious or political groups
ORDINAL: "first", "second", etc.
ORG: Companies, agencies, institutions, etc.
PERCENT: Percentage, including "%"
PERSON: People, including fictional
PRODUCT: Objects, vehicles, foods, etc. (not services)
QUANTITY: Measurements, as of weight or distance
TIME: Times smaller than a day
WORK_OF_ART: Titles of books, songs, etc.
2.4 词向量与相似性
词向量是自然语言处理中一种重要的表示方式,它将单词映射为实数向量。这种表示方式能够捕捉单词之间的语义关系,并将语义信息转化为计算机能够处理的数值形式。
传统的自然语言处理方法往往将文本表示为离散的符号,例如独热编码或者词袋模型。然而,这种方法忽略了单词之间的语义相似性,而且维度过高,造成稀疏性问题。相比之下,词向量通过将每个单词映射到连续的向量空间中,可以更好地捕捉单词之间的语义关系,并且降低了特征空间的维度,使得文本处理更加高效。通过计算两个词向量之间的距离或夹角可以衡量词向量的相似性。
提取句子中每一个词的词向量代码如下:
import spacy
# 加载中文模型"zh_core_web_sm"
nlp = spacy.load("zh_core_web_sm")
# 对给定文本进行分词和词性标注
tokens = nlp("东方明珠是一座位于中国上海市的标志性建筑!")
# 遍历分词后的每个词语
for token in tokens:
# 输出词语的文本内容、是否有对应的向量表示、向量范数和是否为未登录词(Out-of-vocabulary,即不在词向量词典中的词)
print(token.text, token.has_vector, token.vector_norm, token.is_oov)
东方 True 11.572288 True
明珠 True 10.620552 True
是 True 12.337883 True
一 True 12.998204 True
座位 True 10.186406 True
于 True 13.540245 True
中国 True 12.459145 True
上海市 True 12.004954 True
的 True 12.90457 True
标志性 True 13.601862 True
建筑 True 10.46621 True
! True 12.811246 True
如果想得到某个句子或者某个词的词向量,代码如下:
# 该词向量没有归一化
tokens.vector.shape
(96,)
spaCy提供了similarity函数以计算两个文本向量的相似度。
示例代码如下:
import spacy
# 为了方便这里使用小模型,推荐使用更大的模型
nlp = spacy.load("zh_core_web_sm")
doc1 = nlp("东方明珠是一座位于中国上海市的标志性建筑")
doc2 = nlp("南京长江大桥是金陵四十景之一!")
# 计算两个文本的相似度
print(doc1, "<->", doc2, doc1.similarity(doc2))
东方明珠是一座位于中国上海市的标志性建筑 <-> 南京长江大桥是金陵四十景之一! 0.5743045135827821
在上面代码中相似度计算方式默认使用余弦相似度。余弦相似度范围为0到1,数值越高表明词向量越相似。一般来说词向量相似度使用spacy通用模型准确度可能很低,可以尝试使用专用模型或者自行训练模型,spacy推荐使用sense2vec来计算模型相似度。
此外如果仅仅使用spacy提取文本向量,可以用numpy手动计算文本相似度,代码如下:
import numpy as np
import spacy
nlp = spacy.load("zh_core_web_sm")
doc1 = nlp("东方明珠是一座位于中国上海市的标志性建筑")
doc2 = nlp("南京长江大桥是金陵四十景之一!")
# 获取doc1和doc2的词向量
vec1 = doc1.vector
vec2 = doc2.vector
# 使用NumPy计算相似度得分,np.linalg.norm(vec1)就是doc1.vector_norm
similarity_score = np.dot(vec1, vec2) / (np.linalg.norm(vec1) * np.linalg.norm(vec2))
print(doc1, "<->", doc2,similarity_score)
东方明珠是一座位于中国上海市的标志性建筑 <-> 南京长江大桥是金陵四十景之一! 0.5743046
3 spaCy结构体系
3.1 spaCy处理流程
当在一个文本上调用nlp模型时,spaCy首先对文本进行分词处理,生成一个Doc对象。接着,Doc对象将在几个不同的步骤中进行处理。训练好的处理流程通常包括词性标注器、依存句法解析器和实体识别器等处理组件。这些组件相互独立,每个处理流程组件都会返回处理后的Doc对象,然后将其传递给下一个组件。
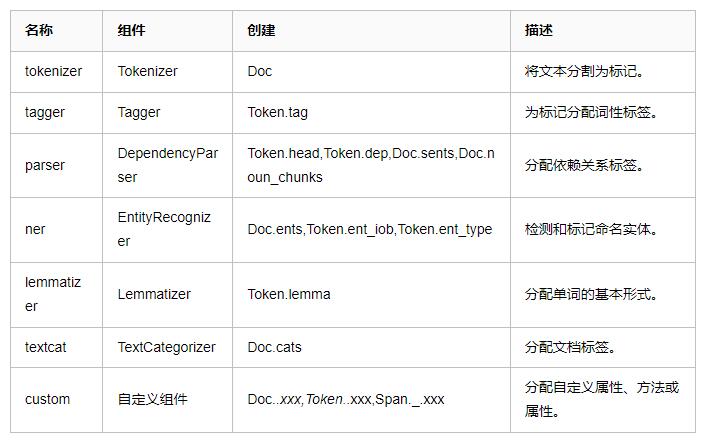
最终生成的Doc对象是一个包含了所有单词和标点符号的序列,每个单词被表示为Token对象。每个Token对象包含了单词本身的内容、词性标注、词形还原后的形式等信息。以下图片解释了使用spaCy进行文本处理的过程。

如上图所示,模型管道中所涉及到的模块主要取决于该模型的结构和训练方式。其中分词tokenizer是一个特殊的组件且独立于其他组件之外,这是因为其他组件模块在调用前都会先调用tokenizer以对字符串进行分词。所有支持主要的模块如下,这些模块的使用已在前一章进行介绍。
一个spacy的模型所支持的文本处理组件查看方式如下:
import spacy
# 加载中文模型"zh_core_web_sm"
nlp = spacy.load("zh_core_web_sm")
# 查看所支持的组件
nlp.pipe_names
['tok2vec', 'tagger', 'parser', 'attribute_ruler', 'ner']
基于以下代码可以控制组件的选择和使用,以加快执行速度:
# 加载不包含命名实体识别器(NER)的管道
nlp = spacy.load("zh_core_web_sm", exclude=["ner"])
# 查看所支持的组件
nlp.pipe_names
['tok2vec', 'tagger', 'parser', 'attribute_ruler']
# 只启用tagger管道
nlp = spacy.load("zh_core_web_sm",enable=[ "tagger"])
nlp.pipe_names
['tagger']
# 加载词性标注器(tagger)和依存句法解析器(parser),但不启用它们
nlp = spacy.load("zh_core_web_sm", disable=["tagger", "parser"],)
# 禁用某些组件
nlp.disable_pipe("ner")
nlp.pipe_names
['tok2vec', 'attribute_ruler']
3.2 spaCy工程结构
spaCy中的中心数据结构是Language类、Vocab和Doc对象。Language类用于处理文本并将其转换为Doc对象。它通常存储为一个名为nlp的变量。Doc对象拥有令牌序列及其所有注释。通过在Vocab中集中字符串、词向量和词法属性。这些主要类和对象的介绍如下所示:
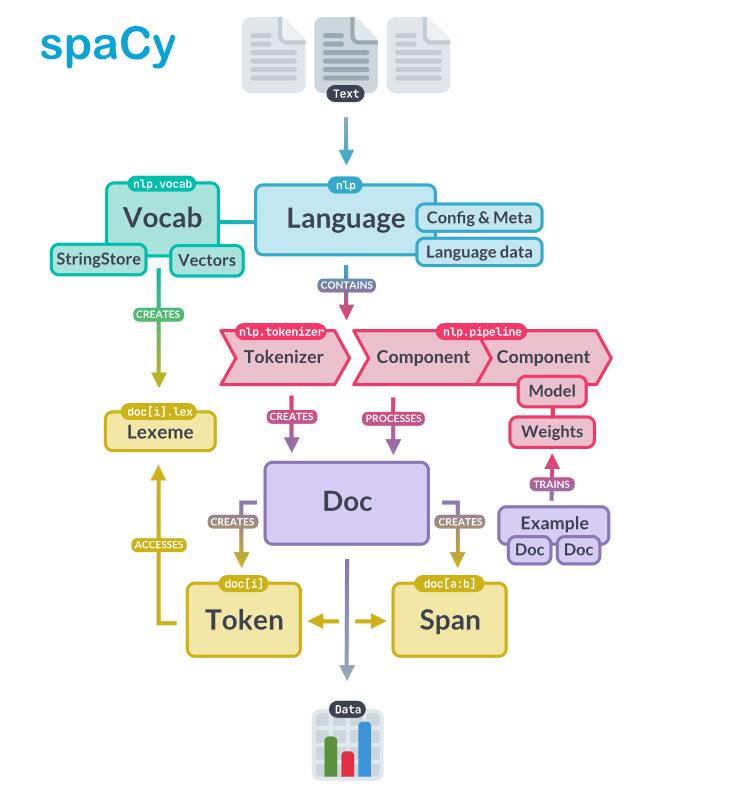
常用模块的介绍如下:
Doc
Doc是spaCy中一个重要的对象,它代表了一个文本文档,并包含了文本中的所有信息,如单词、标点、词性、依赖关系等。可以通过spaCy的Language对象对文本进行处理,得到一个Doc对象。
DocBin
DocBin 是用于高效序列化和反序列化Doc对象的数据结构,以在不同的过程中保存和加载Doc对象。使用代码如下:
# 导入所需的库
import spacy
from spacy.tokens import DocBin
# 加载英文预训练模型
nlp = spacy.load("en_core_web_sm")
# 定义待处理文本
texts = ["This is sentence 1.", "And this is sentence 2."]
# 将每个文本转化为Doc对象,用nlp处理并保存到docs列表中
docs = [nlp(text) for text in texts]
# 创建一个新的DocBin对象,用于保存文档数据,并启用存储用户数据的功能
docbin = DocBin(store_user_data=True)
# 将每个Doc对象添加到DocBin中
for doc in docs:
docbin.add(doc)
# 将DocBin保存到文件中
with open("documents.spacy", "wb") as f:
f.write(docbin.to_bytes())
# 从文件中加载DocBin
with open("documents.spacy", "rb") as f:
bytes_data = f.read()
# 从字节数据中恢复加载DocBin对象
loaded_docbin = DocBin().from_bytes(bytes_data)
# 使用nlp.vocab获取词汇表,并通过DocBin获取所有加载的文档
loaded_docs = list(loaded_docbin.get_docs(nlp.vocab))
# 输出加载的文档
loaded_docs
[This is sentence 1., And this is sentence 2.]
Example
Example用于训练spaCy模型,它包含了一个输入文本(Doc)和其对应的标注数据。关于spaCy模型的训练,见:spaCy-training
Language
Language是spaCy的核心对象之一,它负责处理文本的预处理、词性标注、句法分析等任务。可以通过spacy.load()来加载一个具体的语言模型,获取对应的Language对象。
Lexeme
Lexeme 是一个单词在词汇表中的表示,它包含了关于该单词的各种信息,如词性、词频等。示例代码如下
nlp = spacy.load("en_core_web_sm")
# 定义一个单词
word = "hello"
# 获取单词对应的词元(lexeme)
lexeme = nlp.vocab[word]
# 打印词元的文本内容、是否为字母(alphabetical)
# 是否为停用词(stopword)\是否为字母(is_alpha),是否为数字(is_digit),是否为标题(is_title),语言(lang_)
print(lexeme.text, lexeme.is_alpha, lexeme.is_stop, lexeme.is_alpha, lexeme.is_digit, lexeme.is_title, lexeme.lang_)
hello True False True False False en
事实上对于Lexeme,只要可能,spaCy就会尝试将数据存储在一个词汇表Vocab中,该词汇表将由多个模型共享。为了节省内存,spaCy还将所有字符串编码为哈希值。
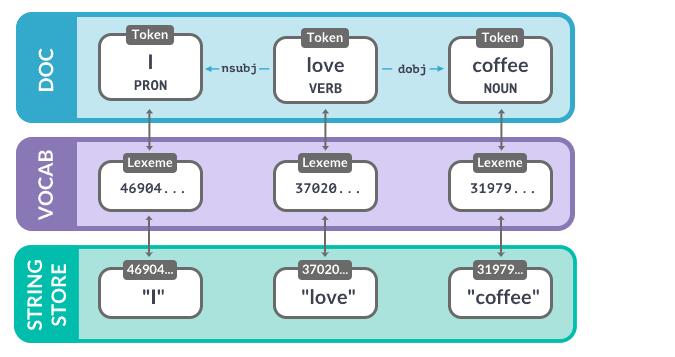
如下所示,不同模型下“coffee”的哈希值为3197928453018144401。但是注意的是只是spaCy这样做,其他自然语言处理库不一定这样做。
import spacy
nlp = spacy.load("zh_core_web_sm")
doc = nlp("I love coffee")
print(doc.vocab.strings["coffee"]) # 3197928453018144401
print(doc.vocab.strings[3197928453018144401]) # 'coffee'
3197928453018144401
coffee
import spacy
nlp = spacy.load("en_core_web_sm")
doc = nlp("I love coffee")
print(doc.vocab.strings["coffee"]) # 3197928453018144401
print(doc.vocab.strings[3197928453018144401]) # 'coffee'
3197928453018144401
coffee
Span
Span 是一个连续的文本片段,可以由一个或多个Token组成。它通常用于标记实体或短语。
nlp = spacy.load("zh_core_web_sm")
text = "东方明珠是一座位于中国上海市的标志性建筑!"
doc = nlp(text)
# 从doc中选择了第0个和第1个词元(token)组成的片段。
# 注意,spaCy中的词元是文本的基本单元,可能是单词、标点符号或其它词汇单位。
# 这里东方、明珠是前两个词
span = doc[0:2]
print(span.text)
东方明珠
4 参考

