
1.无效数据的概念
无效数据是指不符合数据收集目的或数据收集标准的数据。这些数据可能来自于不准确的测量、缺失值、错误标注、虚假的数据源或其他问题。无效数据可能会对数据分析结果产生误导,因此需要在数据分析之前进行过滤和处理。
无效数据的类型包括但不限于以下几种:
缺失值:缺失值是指在数据集中没有收集到足够的信息来完全确定其值的数据点。缺失值可以是由于数据收集过程中的误差、数据源的不确定性、数据点之间的相互作用等原因产生的。在数据分析中,缺失值可能会对数据集的质量和模型的准确性产生负面影响。
重复值:重复值是指在数据集中重复出现的数据点。在数据集中,每个数据点都应该是唯一的,即不存在两个相同的数据点。重复值可能会对数据分析和建模产生负面影响,因为它们可能会掩盖数据集中的重要信息。
异常值:异常值是指在数据集中偏离平均值或常见值的数据点。异常值可以是由于数据收集过程中的误差、数据源的不确定性、数据点之间的相互作用等原因产生的。异常值可能会对数据分析和建模产生负面影响,因为它们可能会掩盖数据集中的重要信息,或者导致模型产生错误的结论。
2.无效数据的处理方法
2.1缺失值处理
缺失值处理是指在数据分析过程中,针对数据集中存在缺失值的数据点进行的处理和重新处理。缺失值处理的目的是消除缺失值对数据集的影响,提高数据集的质量和模型的准确性。
缺失值处理的方法包括以下几种:
填充均值:将缺失值填充为数据集中该值所在列的均值。
填充中位数:将缺失值填充为数据集中该值所在列的中位数。
填充最大最小值:将缺失值填充为数据集中该值所在列的最大最小值。
使用其他数据点的信息填充缺失值:根据数据集中的其他数据点的信息,使用统计方法或其他算法来填充缺失值。
删除缺失值:将缺失值所在的数据点从数据集中删除。
在处理缺失值时,需要根据具体情况进行决策。填充均值和使用其他数据点的信息填充缺失值通常适用于数据集中存在少量缺失值的情况。使用其他数据点的信息填充缺失值和删除缺失值适用于数据集中存在大量缺失值的情况。此外,缺失值处理的方法也需要考虑到数据集的完整性和一致性,以确保数据分析和建模的准确性。
案例演示
首先导入我们演示的数据集
import pandas as pd
import numpy as np
import warnings
warnings.filterwarnings('ignore')
data = pd.read_csv('test.csv')
data
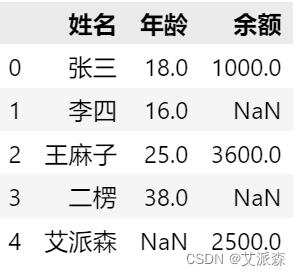
我们可以使用isnull来查看缺失值个数
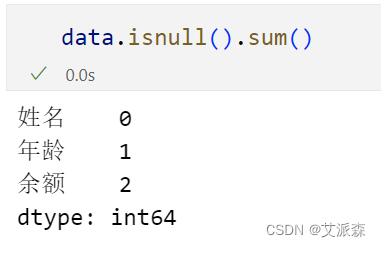
可以看出姓名列是没有缺失值,年龄列有1个缺失值,余额列有两个缺失值。
1.填充均值
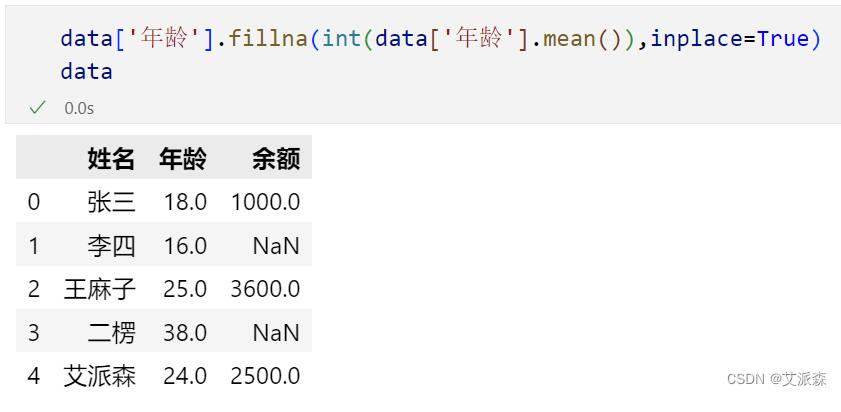
比如我们想要将年龄列中的缺失值用均值来填充,首先可以看一下年龄列均值是多少

接着使用fillna()函数填充缺失值,第一个参数是填充的值,这里我们使用年龄的均值,也就是前面的24.25,可以使用int()转化为整数,inplace=True表示在原数据上修改,默认为False。修改之后我们再次查看数据发现年龄列的缺失值已经使用均值24填充。
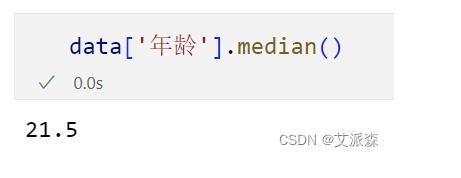
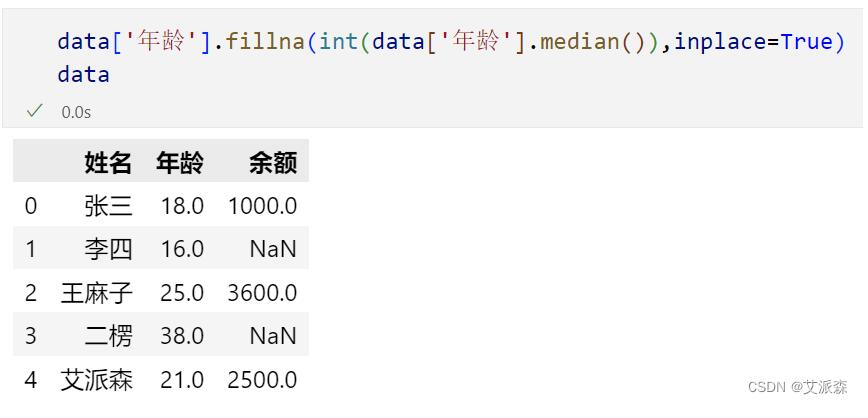
2.填充中位数
还是以年龄为例,查看年龄列的中位数
使用中位数进行填充
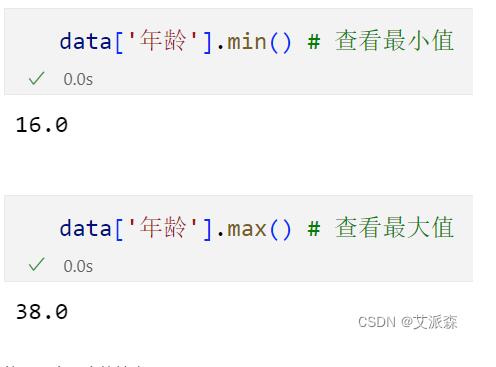
3.填充最大最小值
以年龄为例,查看最大最小值
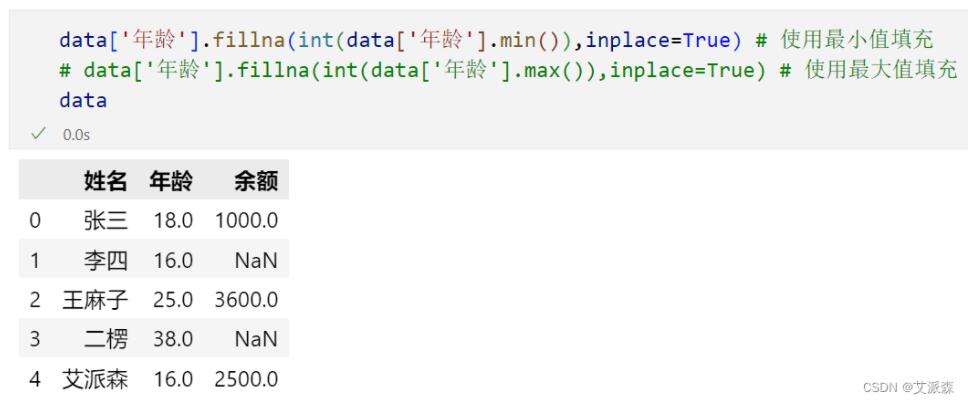
使用最大最小值填充
4.前向填充/后向填充
前向填充就是将缺失值所在位置的上一个值作为填充值填充缺失数据。
后向填充就是将缺失值所在位置的下一个值作为填充值填充缺失数据。
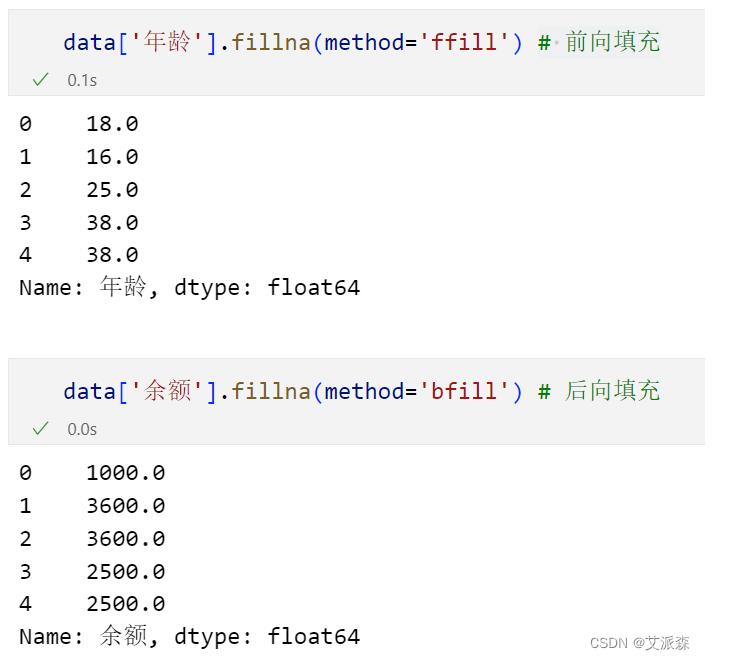
但是如果我们在使用后向填充的时候,最后一个数据是缺失值的话,那么最后一个缺失值将会遗漏。所以我们可以前向和后向结合起来就可以做到万无一失,比如下面的示范:
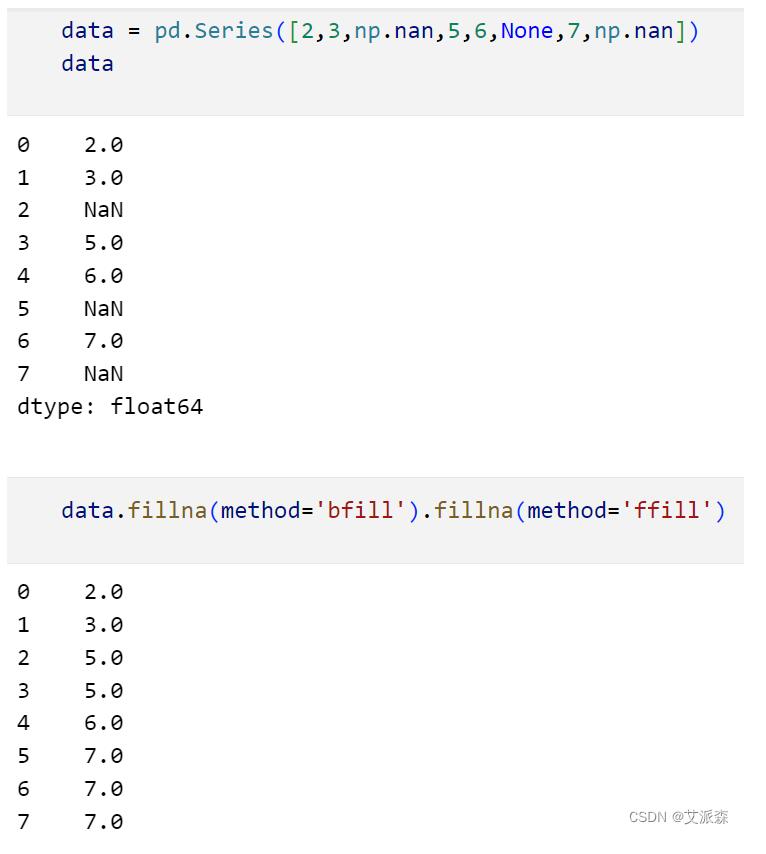
5.删除缺失值
删除的话直接使用dropna即可,需要在原数据上操作的话可以加个inplace=True。

2.2重复值处理
重复值的话一般都是采取删除处理,因为相同的数据出现了n次都是没有意义的,一次就够。
案例演示
首先导入演示数据集

我们可以先使用any函数和duplicated函数来检测数据是否存在重复值,如果返回结果为True说明数据存在重复值;如果返回结果为False说明数据不存在重复值。
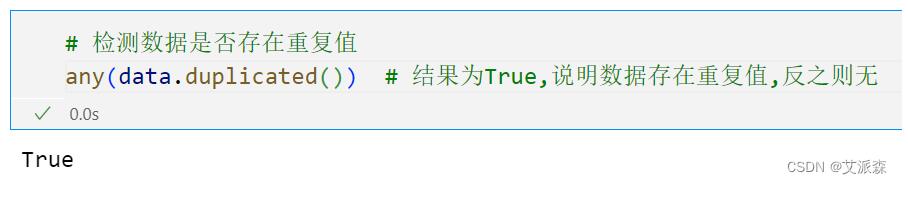
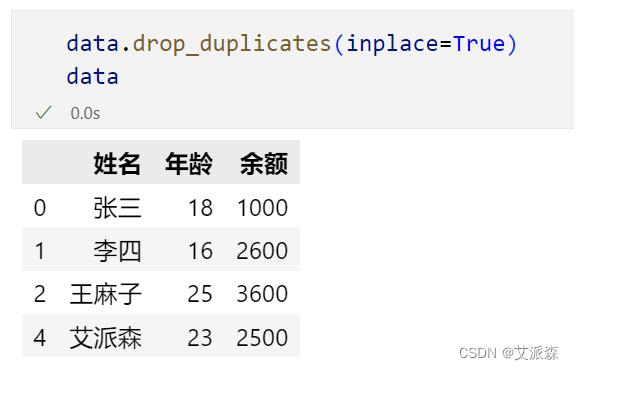
前面我们导入数据的时候就发现李四数据是有重复的,所以这里检测的结果为True。删除的话直接使用drop_duplicates函数即可。
2.3异常值处理
异常值是指在数据集中偏离通常模式或规律的值,可以是正常情况的异常值,也可以是异常情况的异常值。
正常情况的异常值。比如我们想建立居民收入水平的时候,那些收入极其高或低极端数据会影响模型的效果,所以我们一般要进行剔除。
异常情况的异常值。比如数值型变量中出现负数或其他不符合常理的值等等。
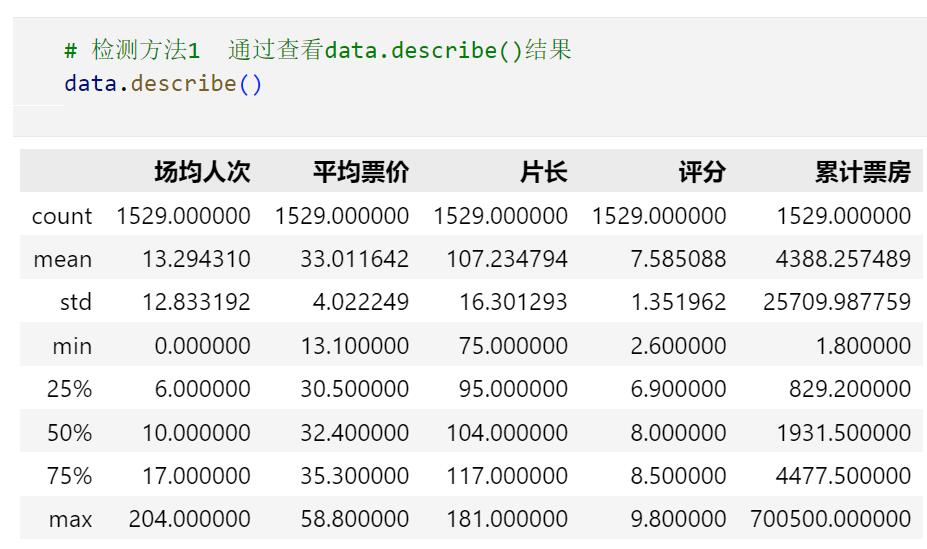
检测方法1
使用describe()方法来查看数值型变量是否存在极端值
检测方法2
通过画出箱线图的方式来展示数据分布情况
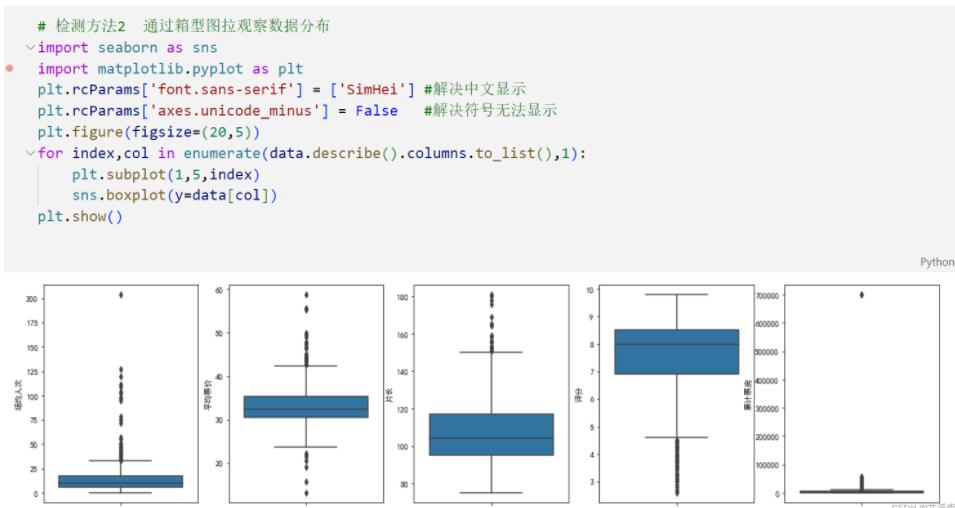
比如上图中的第五幅图就明显存在极端值。
处理的方法就是剔除这些异常数据,这个方式很灵活。比如前面我们发现累计票房一般都是在100000以内,却出现了700000的极端数据,我们就可以采取以下方式挑选出正常数据:

如果我们有多个条件的话可以使用()和&/|字符来结合使用,&表示and交集的意思,|表示or并集的意思。比如下图我们就挑选出累计票房小于100000并且场均人次小于100的数据:

3.如何避免无效数据?
那我觉得就需要在获取数据的源头来防止无效数据的产生,这样也能较少花在处理无效数据的时间成本上。获取数据一般就是通过爬虫获取或从数据库中提取。爬虫的话,在编写代码时可以采取适当的过滤措施,比如某个字段出现空值或异常值,你可以将这条数据不进行保存。从数据库提取的话,在sql上加一些去重/去空的语句即可。
4.实战案例
关于处理无效数据,我在之前的数据分析文章都用到过,大家可以了解一些。
————————————————

